
OpenAI dropped GPT-5.4 mini and nano on March 17, and the headline numbers are genuinely impressive. The mini variant runs more than twice as fast as its predecessor while scoring 54.4% on SWE-Bench Pro, closing most of the gap with the full GPT-5.4 model’s 57.7%. It costs $0.75 per million input tokens and $4.50 per million output tokens. For anyone who’s been following the local AI hardware space, those numbers create an uncomfortable question: at what point does cloud AI become so cheap that spending $2,000 to $4,000 on dedicated local hardware stops making sense?
That question matters because the local AI ecosystem has been on a tear. AMD’s Strix Halo chips finally put 128GB of unified memory in a mini PC, NVIDIA’s DGX Spark promises desktop-class AI compute, and Microsoft’s BitNet framework runs 1-bit models on budget CPUs with no GPU required. Each of these developments makes local AI more capable. But GPT-5.4 mini represents the other side of the equation: cloud AI getting cheaper and faster at an equally relentless pace. Understanding where each approach actually wins requires looking past the marketing on both sides.
The Benchmarks That Actually Matter
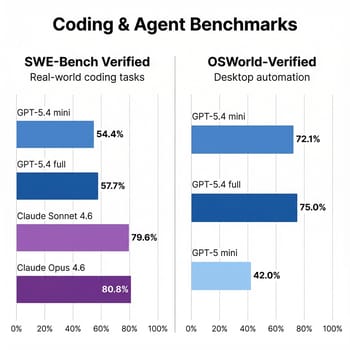
Two numbers from this release genuinely stand out. On OSWorld-Verified, which tests a model’s ability to autonomously control a desktop through screenshot interpretation, mini scores 72.1% compared to just 42.0% for the previous GPT-5 mini. That’s not an incremental improvement; it’s a generational leap that puts a $0.75-per-million-token model within striking distance of the full GPT-5.4’s 75.0%. For anyone building automated workflows that need to interact with desktop applications, that capability at that price is remarkable.
Tool calling shows a similar pattern. On tau2-bench, a telecom-focused benchmark for structured tool use, mini hits 93.4% compared to GPT-5 mini’s 74.1%. On MCP Atlas, which tests model context protocol integration, it reaches 57.7% versus 47.6%. These gains matter because reliable tool use is increasingly the bottleneck in agentic AI systems. A model that can consistently call the right function with the right parameters is more valuable in practice than one that writes slightly better prose.
But here’s where the honest assessment diverges from the press release. On SWE-Bench Pro, GPT-5.4 mini’s 54.4% is respectable for a small model. The picture changes on SWE-Bench Verified, where Claude Opus 4.6 and Sonnet 4.6 both score around 80%, demonstrating substantially stronger software engineering capabilities. Sonnet achieves this at just $3 per million input tokens. These are different benchmarks with different difficulty levels, but the directional gap is real: for serious software engineering tasks, frontier models remain far ahead of mini-class models. The mini model also falls apart on long-context retrieval: 47.7% on OpenAI’s MRCR v2 benchmark with 8 needles at 64K-128K context, compared to 86.0% for the full GPT-5.4. If your workflow involves analyzing large codebases or tracking many details across long documents, mini is not a replacement for a frontier model.
What This Costs in the Real World
Benchmark scores only tell half the story. What actually matters is how these numbers translate to monthly costs for real usage patterns. Consider three scenarios that represent how most people interact with AI tools.
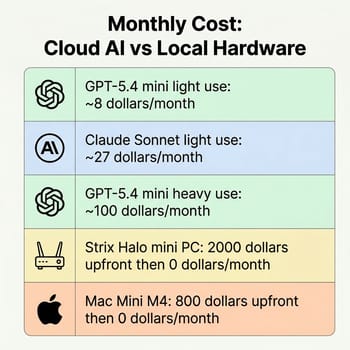
A light user doing 10 to 20 coding sessions per day, each consuming roughly 10,000 input tokens and 2,000 output tokens, would spend about $5 to $10 per month on GPT-5.4 mini once you factor in the $4.50 per million output token cost. The same usage on Claude Sonnet 4.6 runs $18 to $36, reflecting both higher per-token pricing and substantially stronger performance. A heavy developer generating 50 to 100 sessions daily with longer context windows might spend $50 to $150 per month on mini. Cloud AI is genuinely cheap for light to moderate use, but the costs add up faster than the headline input pricing suggests, and heavy users start closing the gap with a one-time hardware investment.
But cost is not the only variable. A Strix Halo mini PC with 128GB of unified memory can run 70B-parameter models locally with zero per-token costs, complete data privacy, and no internet dependency. The upfront investment pays for itself in roughly 12 to 24 months for heavy users, and you get hardware that serves many other purposes. A Mac Mini M4 running local models through frameworks like Ollama or LM Studio offers a similar value proposition with excellent energy efficiency. The comparison isn’t simply cloud versus local. It’s about which constraints matter more for your specific situation: upfront cost and hardware limitations, or ongoing costs and privacy tradeoffs.
The Subagent Pattern and Why Mini Models Matter More Than You Think
The most interesting implication of GPT-5.4 mini isn’t what it can do alone. It’s what it enables as part of a larger system. OpenAI is openly encouraging a subagent architecture where a frontier model like GPT-5.4 handles planning and decision-making while mini agents execute narrower tasks in parallel: searching codebases, reviewing files, processing documents. In Codex, mini uses only 30% of the GPT-5.4 quota, letting developers handle simpler coding tasks at roughly one-third the cost.
This pattern isn’t unique to OpenAI. Claude Code uses a similar approach, and the broader AI industry is converging on multi-model architectures where different tiers handle different complexity levels. What GPT-5.4 mini represents is that the workhorse tier just got substantially more capable. A model that can autonomously navigate desktop applications at 72.1% accuracy and call tools at 93.4% reliability doesn’t need a frontier model supervising every step. That makes the overall system both cheaper and faster, which is the real “2x improvement” OpenAI is selling.
For the developers buying Mac Minis to run AI agents 24/7, this creates an interesting hybrid possibility. Run a local model for sensitive tasks and private data, but offload the high-volume, latency-sensitive subtasks to GPT-5.4 mini or nano through the API. The monthly cost of the cloud portion would be trivial compared to the hardware investment you’ve already made, and you’d get capabilities like computer use that most local models simply can’t match yet.
Where Local AI Still Wins
None of this means local AI hardware is obsolete. There are genuine advantages that no amount of API pricing can address, and they matter more to some users than others.
Privacy is the obvious one. If you’re working with confidential code, patient data, or anything subject to regulatory compliance, sending tokens to OpenAI’s servers isn’t an option regardless of price. Running a 70B model locally on a Strix Halo system gives you full control over your data, and the quality gap between open-source models like Llama 3.3 and cloud APIs has narrowed considerably in the past year.
Latency is another factor that benchmarks miss. A local model responds in milliseconds with no network round-trip. For interactive coding workflows where you’re completing lines of code or generating quick suggestions, the difference between a local model and even a fast API call is perceptible. Microsoft’s BitNet framework pushes this advantage further by enabling 1-bit models that run at remarkable speeds on ordinary CPUs, even if the quality tradeoff means they’re best suited to simpler tasks.
Reliability matters too. Cloud APIs have rate limits, outages, and pricing changes. OpenAI has raised prices before, and GPT-5.4 mini already costs two to three times more than the GPT-5 mini it replaced. A local setup doesn’t have a terms of service that can change next quarter. For anyone running AI infrastructure on dedicated hardware, that stability has real value.
The Honest Bottom Line
GPT-5.4 mini is genuinely good, and the pricing makes it accessible for a wider range of projects than any previous model at this capability level. The computer use and tool calling improvements are not incremental; they represent a step change in what small models can do. For developers building agentic systems, classification pipelines, or automated workflows, mini at $0.75 per million tokens is difficult to argue against.
But calling this a paradigm shift would be overselling it. Claude Opus 4.6 and Sonnet 4.6 still dominate software engineering benchmarks by a wide margin. Local AI hardware still wins on privacy, latency, and long-term cost predictability. The $0.75 pricing sounds cheap until you multiply by enterprise-scale token volumes, and the two-to-three-times price increase over GPT-5 mini is a reminder that cloud AI prices don’t always go down.
The real takeaway isn’t that one approach beats the other. It’s that the gap between “cheap cloud AI” and “expensive local hardware” is narrowing from both directions. Cloud models keep getting cheaper and more capable. Local hardware keeps getting more memory and better inference speeds. The sweet spot for most people in 2026 is probably some combination of both: a local model for private, latency-sensitive work and a cloud API for everything else. GPT-5.4 mini just made the cloud side of that equation significantly more attractive.


