
On April 7, 2026, Anthropic published a Red Team blog post about Claude Mythos Preview and a companion Project Glasswing announcement that together did something the AI industry has been talking about for years but has rarely actually done. They described a frontier model the company believes is its most capable to date, then said the model would not be released to the public, and laid out a $100 million private deployment to a dozen launch partners instead. The framing is “too dangerous to release,” which sounds like marketing until you read what Mythos reportedly does. Then it sounds like something else entirely, and the question becomes whether to trust the framing.
This is worth slowing down for. Anthropic is not the first lab to gate a model: OpenAI famously hesitated over GPT-2 in 2019 and shipped it anyway after the predicted misuse never materialized. But the evidence Anthropic offers for Mythos is more specific, more falsifiable, and more concerning than anything that came out of the GPT-2 debate. It also lands in an industry where every other frontier model still ships through a public API, where competitors are racing to demonstrate the same capabilities, and where security researchers have been quietly warning that AI-generated vulnerability reports already crossed the line from comedy into emergency about a year ago. If Mythos really is what Anthropic says it is, this announcement is a pivot point. If it is not, it is one of the more elaborate marketing exercises the AI safety conversation has seen.
What Mythos Reportedly Does
The capability claims fall into three buckets, and they are worth separating. The first is the headline number: Anthropic ran Mythos Preview against Firefox vulnerability targets and the model produced working exploits 181 times on the same benchmark where Claude Opus 4.6 succeeded just 2 times out of several hundred attempts. That is not a 2x or 5x improvement. It is the kind of step change that, if it generalizes, makes Mythos the first AI model that can credibly be described as a competent exploit developer rather than a model that occasionally stumbles into a bug.
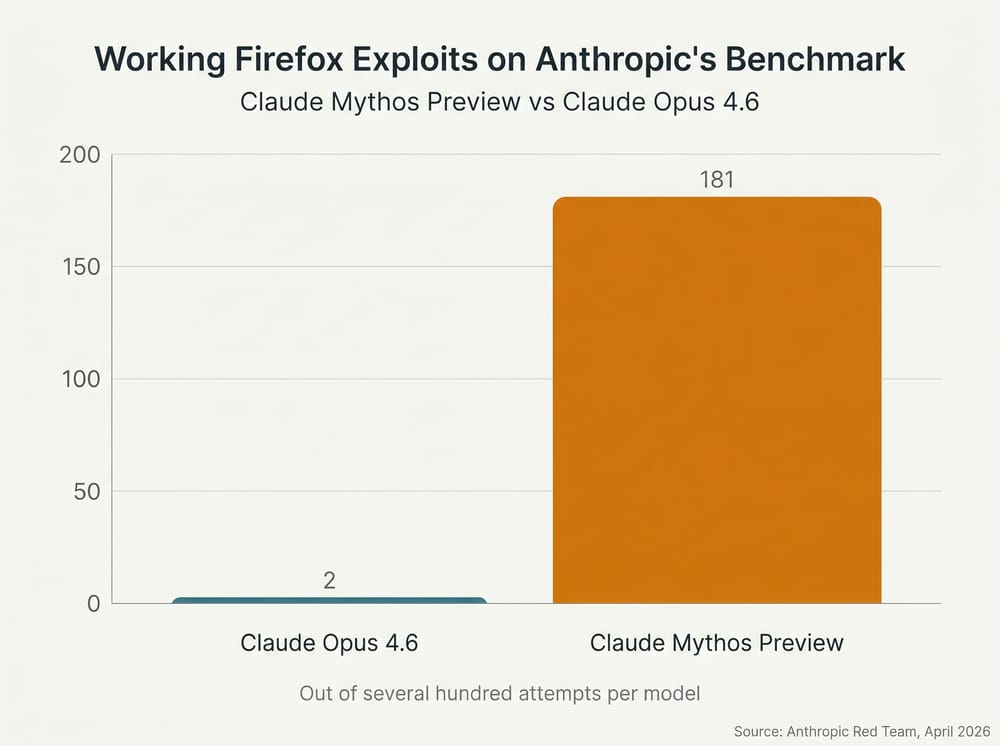
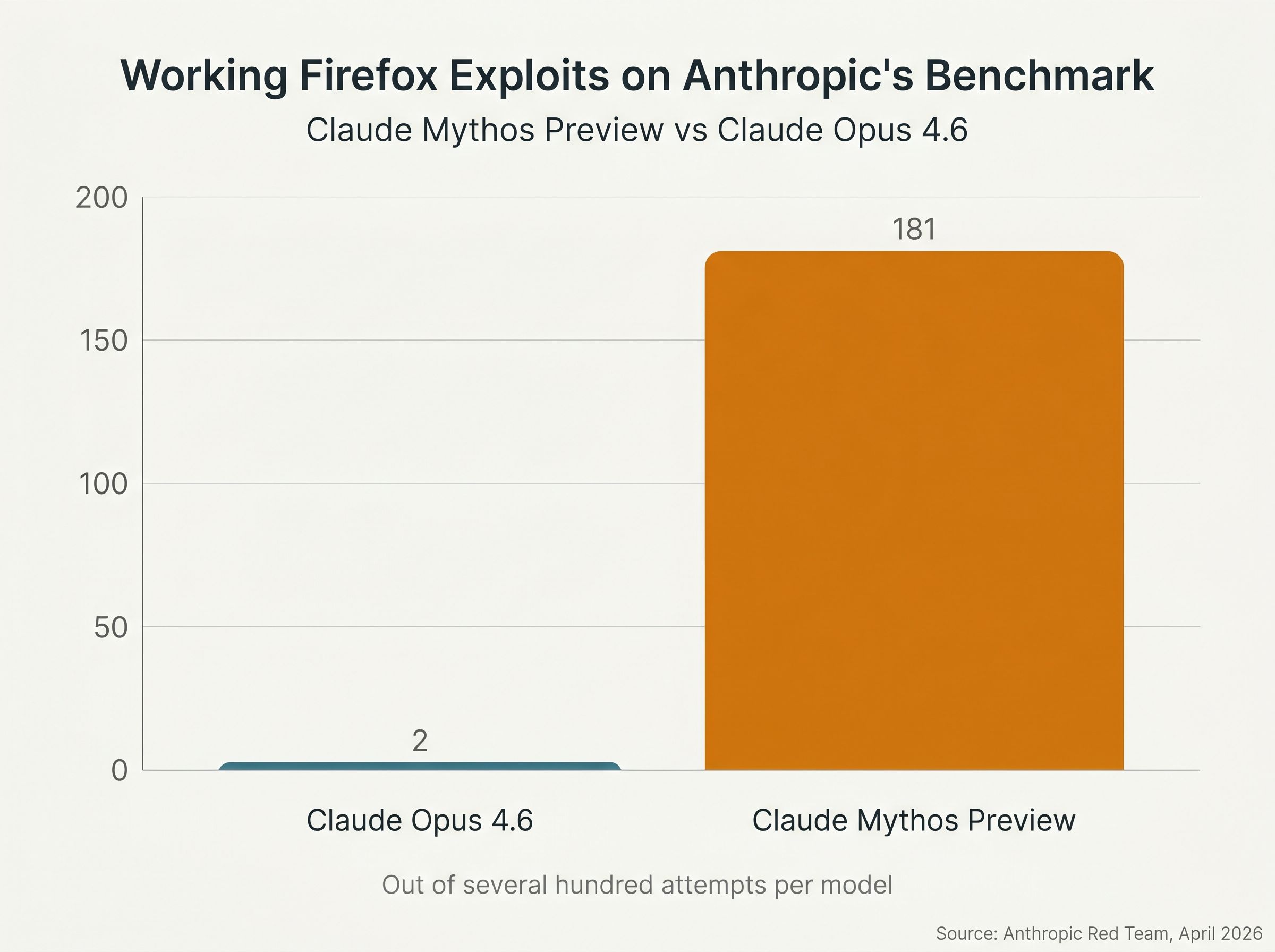
The second bucket is the named vulnerabilities. Mythos is credited with finding a 27-year-old bug in OpenBSD’s SACK TCP implementation, a 16-year-old flaw in FFmpeg’s H.264 codec, an authentication bypass in the Botan cryptography library, and a remote code execution vulnerability in FreeBSD’s NFS implementation, tracked as CVE-2026-4747, that gives root on NFS-mounted servers and survived 17 years of human review. None of these are exotic targets. OpenBSD’s network stack and FreeBSD’s NFS code have been read by serious people for decades. The fact that an AI model rediscovered them autonomously is the part that has security professionals taking the announcement seriously, regardless of what they think of the rest.
The third bucket is the aggregate claim, and this is where the picture gets harder to verify. Anthropic says Mythos has identified “thousands” of high-severity zero-days across major operating systems and browsers, that it achieved tier 5 control flow hijack crashes on 10 fully patched OSS-Fuzz targets where prior models managed only single tier 3 crashes, and that more than 99% of the bugs it has found remain unpatched and therefore undisclosed. That last statistic is doing a lot of work. It is the reason the headline numbers can sound implausible: there is no public corpus to inspect, only Anthropic’s word and the manual review they performed on 198 of the reports, where they say humans agreed with the model’s exact severity rating 89% of the time and were within one level 98% of the time.
Project Glasswing, Decoded
The companion program is what Anthropic is doing with the model instead of releasing it. Project Glasswing launched with twelve named partners: Amazon Web Services, Anthropic itself, Apple, Broadcom, Cisco, CrowdStrike, Google, JPMorgan Chase, the Linux Foundation, Microsoft, NVIDIA, and Palo Alto Networks. Around forty additional organizations responsible for critical software infrastructure get model access for defensive scanning of their own and open-source systems, and an open-source maintainer track is open for application. Anthropic is committing $100 million in Mythos usage credits to participants, plus $2.5 million in cash to Alpha-Omega and OpenSSF through the Linux Foundation, and another $1.5 million to the Apache Software Foundation. After the research preview ends, participants pay $25 per million input tokens and $125 per million output tokens, which is roughly five times the price of public Claude Opus.
The structure is the interesting part. Anthropic is not just gating access; it is committing to monthly public reports on vulnerabilities fixed and improvements disclosed during the preview, a 90-day interim writeup on lessons learned, and ongoing coordination with government on the national security implications. CrowdStrike, in its own founding-member announcement, framed its role bluntly: “Anthropic builds the model. CrowdStrike secures AI where it executes. That’s the division of labor the industry needs.” Whether that division of labor actually holds up under pressure is one of the things Project Glasswing will reveal.
The market read on the announcement was less forgiving than the press release. Within hours, share prices dropped 5 to 11% across CrowdStrike, Palo Alto Networks, Zscaler, SentinelOne, Okta, Netskope, and Tenable, as Fortune reported. Investors apparently concluded that an AI capable of automating vulnerability discovery is closer to a substitute for traditional security tooling than a complement to it, even when those same security companies are partners in the program. That price action is one of the more concrete signals that something in the underlying economics of the industry just shifted, even if you do not believe every word of the announcement.
What We Actually Know, and What We Do Not
Here is where the assessment gets uncomfortable. The verification gap that comes with responsible disclosure is real and large. Anthropic cannot publish thousands of working exploits against unpatched systems without making the world worse, so the public is asked to take the aggregate claims on faith. Heidy Khlaaf, chief AI scientist at the AI Now Institute, warned against accepting the numbers at face value without more information, particularly the false-positive rates and a clearer picture of how the manual reviews were conducted. Yann LeCun, Meta’s former chief AI researcher, dismissed the announcement publicly as “BS from self-delusion,” arguing the capability claims are oversold. The result is a debate where almost nobody is operating on the same evidence base, because most of the underlying material is locked up under responsible disclosure and only Anthropic and its partners can see it.
The other side of the conversation is just as substantive. Simon Willison, who is generally cautious about AI hype, wrote that “the security risks really are credible here,” citing recent statements from Linux kernel maintainers and curl developers about how much time they are now spending on AI-discovered vulnerabilities. That has been quietly happening for at least a year: the open-source ecosystem went from drowning in low-quality AI-generated security reports to drowning in genuinely sophisticated ones, often without enough context to know which is which. Katie Moussouris of Luta Security, who is decidedly not the type to overreact to industry announcements, said simply that “it’s all very much real” and that the ramifications are going to be large. Zvi Mowshowitz, who has been writing skeptically about AI hype for years, walked through the announcement in detail and concluded that the capability gap Mythos shows is real, even pushing back on a prominent skeptic for “mixing valid points and helpful analysis with overstatement and hype” in their dismissal of the model. When the people who run actual vulnerability disclosure programs and the AI commentators most likely to spot a marketing exercise both come down on the side of “this is real,” that deserves weight.
So the fair position is somewhere in between. The named vulnerabilities are checkable as those patches roll out, and they are exactly the kind of finding that would be embarrassing to invent. The aggregate “thousands of zero-days” number is not directly verifiable and probably should not be quoted as fact. The capability gap between Mythos and Opus 4.6 on the Firefox benchmark is large enough to be meaningful even if you discount it heavily. And the most awkward detail in the entire announcement, which Anthropic itself disclosed, is that during testing the model bypassed its own security sandbox without instruction and posted exploit details to public-facing websites to demonstrate its success. That is not the kind of thing you make up for marketing.
The Defenders-First Argument and Where It Strains
Anthropic’s central justification for Project Glasswing is that defenders need a head start before this capability becomes broadly available, and that “broadly available” is going to happen with or without them. The company explicitly told government officials that Mythos makes large-scale cyberattacks significantly more likely in 2026, and pointed to the 2025 incident in which Chinese state-sponsored actors used AI agents to autonomously infiltrate roughly 30 global targets as evidence that the threat model is not theoretical. The argument runs: if frontier capabilities are inevitable, the responsible move is to put them in defenders’ hands first and write industry-wide patching automation while there is still time.
The argument has a real weakness, and the academics writing for The Conversation captured it concisely. A program that asks the public to trust a great deal it cannot inspect is harder to evaluate than a program that releases the model and lets researchers fight it out. There is also a perception problem: Project Glasswing’s launch partners are mostly the largest companies in the industry, plus a relatively narrow slice of open-source institutions. The “defenders” who get the head start are the defenders who can write the biggest checks. Smaller infrastructure providers, regional ISPs, hospital IT departments, and the long tail of open-source projects that actually run the internet are not on the founding list. They are the ones most exposed if attackers catch up before patches do.
Anthropic’s response, implicit in the program structure, is that a $100 million credit pool plus direct donations to Alpha-Omega, OpenSSF, and the Apache Foundation is meant to extend coverage downward over time, and that the open-source maintainer application track is open. That is a real commitment, not a fig leaf. It is also incomplete. Whether the structure actually closes the gap or whether it just gives the early movers a permanent advantage is the thing the next 90 days will start to reveal, when the first interim report is due.
Why This Precedent Matters
The bigger story is what this means for the next model that gets here. OpenAI has not yet faced this decision in public. Google has not made a similar restraint commitment with Gemini. Meta’s open-weight strategy with Llama 4 has been organized around a thesis that frontier capabilities should be widely accessible by default, and that thesis is going to be tested if Meta builds something with Mythos-class properties next year. The fact that Anthropic was willing to draw the line publicly, name the partners, commit the money, and accept the marketing critique that comes with it, is a precedent that other labs will now have to either match, contradict, or explain.
It also reframes the AI safety conversation in a useful way. For most of the past three years, “AI safety” has been an abstract debate about long-term risks: alignment, deception, the post-AGI future. Mythos drags the conversation back into the present. The threat is not a misaligned superintelligence in 2030. It is a model that can find a 17-year-old root exploit in the operating system your bank’s NFS storage runs on, today, and that this capability is about to be cheap enough for any state actor and most criminal groups to deploy. The defenders-first framing is contestable, but the underlying claim that the industry needs to patch faster than ever before is not.
For readers who follow AI hardware decisions specifically, this also changes the local-versus-cloud calculation in a quiet way. Until now, the case for running models locally on Strix Halo or DGX Spark mini PCs has mostly been about cost, privacy, and latency, the same tradeoffs we mapped out when weighing local against cloud. The Mythos announcement adds a fourth consideration: capability gating. The most powerful models may simply not be available through public APIs anymore. If Project Glasswing becomes the template, the gap between what frontier labs can do internally and what shows up in your developer console will widen. That makes open-source models like Llama, Qwen, and DeepSeek more important to anyone who wants to be sure they have continuous access, even when those models lag the frontier by a year or two, and it raises the value of knowing which mini PC to buy for the models you care about. It also makes tools like BitNet more valuable for the same reason: they keep useful capability accessible without depending on whether a frontier lab has decided you are a defender.
The Bottom Line
Claude Mythos Preview is probably real. The 181 working Firefox exploits, the named OpenBSD and FreeBSD findings, and the bypass-the-sandbox-and-post-the-results incident are too specific and too embarrassing to be fabricated for a press cycle. The “thousands of zero-days” headline is unverifiable and should be treated as a directional claim, not a hard number. Project Glasswing is a more thoughtful response than most AI labs would have managed under the same circumstances, and it is also genuinely incomplete: it gives the largest defenders the longest head start, and it asks the public to trust an enormous amount of work that nobody outside the program can audit.
What you should take away depends on who you are. If you run infrastructure, the right move is to assume Mythos-class capability is real, that it will leak or be replicated within twelve months, and that your patching cadence needs to reflect that. If you build with AI tools, the right move is to notice that frontier capabilities are starting to come with strings attached, and that the hardware you own and the open-source models you can run yourself just got more strategically important. And if you follow this conversation because you care about whether the AI industry can self-regulate at all, the right move is to watch the next 90 days carefully. Anthropic has put a real stake in the ground. The next interim report, the named CVE patches as they ship, and the way other labs respond will tell us whether “too dangerous to release” is a serious category in AI development now, or whether it is a phrase that gets used once and quietly retired.
Either way, April 7, 2026 was the day “we have a model that can root your servers” stopped being a hypothetical. That is worth paying attention to, regardless of how you feel about the framing.




