
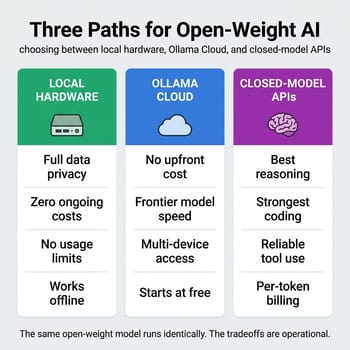
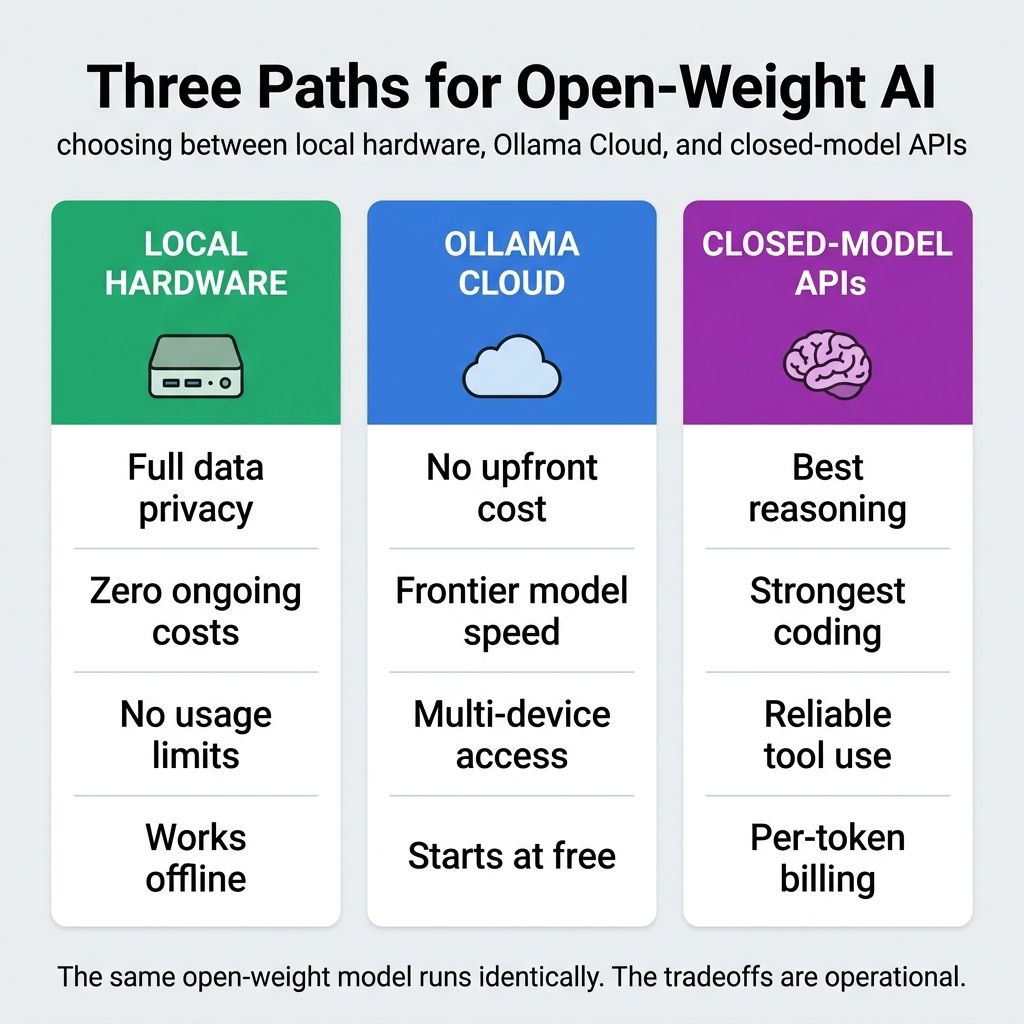
Two months ago, this site published an article asking whether GPT-5.4 mini’s rock-bottom pricing changed the math on local AI hardware. The conclusion was measured: cloud AI keeps getting cheaper, local hardware keeps getting faster, and most people in 2026 probably want some combination of both. That framework assumed two options: run it locally, or call a cloud API. As of late April 2026, there are three.
Ollama Cloud now hosts frontier open-weight models on NVIDIA Blackwell GPUs, accessible through the same ollama run command local users already know, with a :cloud suffix and pricing that starts at free. DeepSeek V4 Pro, Qwen 3.5, GLM-5.1, Kimi K2.6: the same models you would pull to a Strix Halo box or Mac Mini are now running on data center hardware with no local installation required. Ollama’s announcement of DeepSeek V4 Pro on cloud cleared 1,600 likes and 95,000 views in days, and the Qwen 3.5 post hit 1,200 likes and 160,000 views. The interest is real because the question it raises is real: if the model you wanted to run is now hosted for you, why are you spending $2,000 on hardware to run it yourself?
The answer is not “you shouldn’t.” There are genuine reasons to own the hardware, and this article covers them in detail. But Starry Hope’s local AI hardware cluster was built around a two-option world. This article adds the third option and gives you a framework for choosing among all three.
What Ollama Cloud Actually Offers
The model catalog is the headline. DeepSeek V4 Pro runs 1.6 trillion total parameters with 49 billion activated per token and supports a one-million-token context window. Qwen 3.5 spans variants from 0.8B to 397B total parameters, with the larger MoE variants activating only a fraction of their weights per token. GLM-5.1 is Zhipu AI’s flagship with strong coding performance. Kimi K2.6, from Moonshot AI, is a multimodal model designed for long-horizon agentic tasks. All of these are open-weight models you could download and run locally; Ollama Cloud simply runs them on NVIDIA Blackwell GPUs in a data center and streams the output back to you.
The pricing works differently from most cloud AI services. Ollama Cloud bills on GPU-time consumption, not per token. The Free tier provides daily usage quotas for experimentation with one concurrent model session. Pro at $20 per month offers roughly 50 times the Free tier’s capacity with up to three concurrent sessions. Max at $100 per month delivers five times Pro’s capacity with up to ten concurrent sessions and priority access to large MoE models. This GPU-time model means costs scale with how long the GPU is working, not how many tokens it generates, which favors users who send large prompts to big models. The catch is that the exact GPU-minutes per tier are not published, making precise cost comparisons inherently fuzzy. Ollama has also revised its pricing and limits at least twice since launch, so check the official pricing page before making decisions based on the numbers here.
The practical experience mirrors local Ollama almost exactly. You type ollama run deepseek-v4-pro:cloud instead of ollama run deepseek-v4-pro. Your existing workflows, scripts, and API integrations need exactly one change: appending :cloud to the model name. That simplicity is the real product. You are not learning a new API or switching frameworks. You are running the same tool you already know, pointed at faster hardware.
The limits deserve understanding before you commit. Free-tier users get one concurrent session with rolling quotas that reset every few hours. Pro users get three concurrent sessions and weekly rolling limits that are generous for daily development but will cap heavy production workloads. If you hit your cap mid-workflow, you wait for the next reset: a fundamentally different experience from local hardware where compute is always available. Anyone building agent pipelines or batch processing systems should think carefully about whether those concurrency limits match their workload.
When Local Hardware Still Wins
Privacy is the most obvious advantage and the hardest to argue around. When you run DeepSeek V4 Pro on a Strix Halo mini PC sitting on your desk, your prompts and the model’s responses never leave your network. For anyone working with proprietary code, patient data, legal documents, or anything subject to regulatory compliance, that is not a nice-to-have; it is a requirement. The same calculus is why so many small offices set up fully local private transcription on a mini PC rather than uploading sensitive audio. Ollama Cloud’s privacy policy is reasonable for a cloud service, but “reasonable for a cloud service” and “my data never touches a third-party server” are different propositions entirely.
Latency is subtler but equally real for certain workflows. A local model responds in milliseconds with no network round-trip. Independent testing shows DeepSeek V4 running at 23 to 26 tokens per second on Apple Silicon via MLX, and Strix Halo systems push around 72 tokens per second on MoE architectures like Qwen3-30B-A3B. Ollama Cloud running on Blackwell will likely match or exceed those raw generation speeds, but the network adds 50 to 200 milliseconds per round-trip depending on your location and connection. For interactive coding completions where you want instant suggestions, local inference feels noticeably snappier. For longer conversations or batch document processing, the network overhead is negligible relative to generation time.
Volume economics tip decisively once usage crosses a threshold. The independent pricing analysis from Pooya Golchian estimates that an RTX 4090 build breaks even with Ollama Cloud Max above roughly 25,000 daily requests. The same logic applies even earlier to cheaper hardware like a Mac Mini M4. A Mac Mini with M4 chip now starts at $799 after Apple discontinued the $599 base model in May 2026, and ranges up to $1,799 for M4 Pro configurations. If you are running AI workflows eight hours a day, five days a week against Ollama Cloud Max at $100 per month, the hardware pays for itself in 8 to 18 months depending on which Mac Mini you buy. After that point, every token is free. Cloud subscriptions never stop billing.
There is also a category of users for whom budget local hardware offers something no cloud service can match at any price. A $300 Intel N150 mini PC with 16GB of RAM runs 7B models at 6 to 9 tokens per second with no internet connection, no subscription, and no usage limits. For hobbyists experimenting with small models, developers who work offline, or anyone in a region with expensive or unreliable connectivity, that is a complete local AI setup for a one-time investment that would buy 15 months of Ollama Cloud Pro. Taken to its logical extreme, that offline-first thinking is exactly what powers an offline AI survival computer built around a mini PC. On the truly budget end, even 1-bit BitNet models running on a CPU give hardware you already own a basic local assistant for nothing. The r/LocalLLaMA community’s viral thread on the 4B-class models of 2026 underscores the point: small, efficient models are getting remarkably capable, and the hardware to run them keeps getting cheaper.
When Ollama Cloud Wins
The inverse of the volume argument is just as valid: if you are not running AI workloads all day, buying hardware to do it is like buying a commercial oven because you bake cookies twice a month. Ollama Cloud’s Free tier is genuinely free and gives you access to frontier open-weight models that would require thousands of dollars in hardware to run locally at comparable speeds. For developers exploring what DeepSeek V4 Pro or GLM-5.1 can do before committing to a hardware investment, the zero-cost entry point is difficult to beat.
The Pro tier at $20 per month occupies a pricing sweet spot that makes the hardware comparison uncomfortable for intermittent users. Twenty dollars buys you 50 times the Free tier’s capacity with three concurrent sessions and access to the full model catalog running on Blackwell GPUs. For perspective: a Strix Halo GMKtec EVO-X2 at roughly $2,000 amortized over three years costs about $56 per month before you factor in electricity, maintenance, and the opportunity cost of tying up that capital. If your usage fits comfortably within Pro’s limits, the math does not close for hardware on pure economics: amortized hardware costs about $56 per month against Pro’s $20, and that gap is structural, not something you wait out.
Portability is the advantage cloud proponents undersell. A local Strix Halo box is tied to your desk. Ollama Cloud works from any device with an internet connection: your laptop at a coffee shop, your tablet on a train, your phone in an airport. For developers who work across multiple machines, the ability to run ollama run deepseek-v4-pro:cloud from anywhere without syncing model files or managing local installations is genuine convenience. The Yage AI buying guide highlights another angle: Ollama Cloud’s multi-model advantage. If your workflow spans models from different vendors, a single subscription replaces three separate API accounts with three separate billing dashboards.
There is also the “try before you buy” path that hardware marketing never mentions. Spend a month on Ollama Cloud Pro running the exact models you would run locally. Measure your actual usage patterns, discover which models you reach for most, observe whether the concurrency limits and latency bother you. That $20 investment tells you more about whether $2,000 in hardware is justified than any spec sheet or benchmark table ever could. If the month convinces you to buy, you will buy smarter. If it convinces you not to, you just saved yourself a significant chunk of money.
When Closed-Model APIs Still Win
The three-way decision has a third branch that Ollama’s marketing would prefer you forget: for the hardest reasoning and coding tasks, closed-model APIs remain substantially better than anything in the open-weight catalog. Claude Opus 4.6 and Sonnet 4.6 score around 80% on SWE-Bench Verified, the gold standard for automated software engineering, while the best open-weight models trail by a meaningful margin. GPT-5.4 mini’s tool-calling reliability at 93.4% on tau2-bench sets a bar that open-weight alternatives have not matched. If you are using AI for complex code refactoring, multi-step debugging, or agentic workflows that demand reliable function calling, the frontier closed models are worth their per-token pricing.
This matters for Starry Hope readers specifically because many of you are evaluating local AI hardware for coding assistance. The assessment: running DeepSeek V4 Pro locally or on Ollama Cloud gives you a capable coding assistant, but it does not give you a Claude Code or Codex replacement. Those tools are built on frontier closed models because the reliability gap is still wide enough to matter in production workflows. The smart approach is not to pick one tier and abandon the others; it is to use each where it actually performs best. Frontier APIs for your hardest coding and reasoning tasks, Ollama Cloud or local hardware for everything else, with the choice between those two depending on the tradeoffs covered above.
The Math at Three Price Points

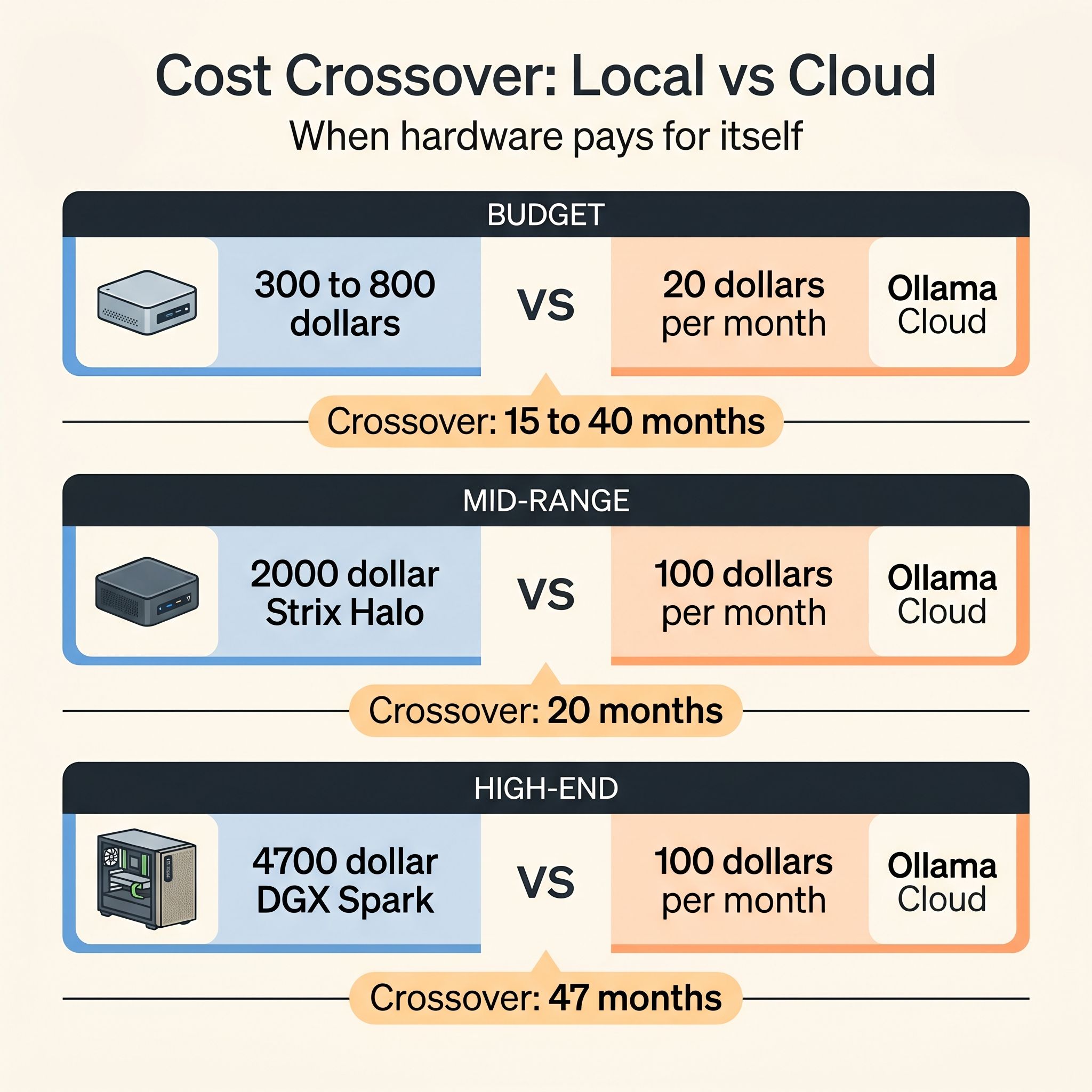
Abstractions are helpful, but you are probably here because you are weighing a specific purchase. Here is the crossover math at three hardware tiers that represent real decisions Starry Hope readers face.
A budget setup between $300 and $800 covers a 16GB Intel N150 mini PC or a base Mac Mini M4 at $799 (the new floor after Apple discontinued the $599 base model in May 2026). Both run 7B to 8B models locally with no ongoing costs. Ollama Cloud Free handles the same models at faster speeds but with usage caps that will frustrate daily drivers. Cloud Pro at $20 per month exceeds both machines’ performance on those same models, and the crossover happens around 15 months for the N150 and 40 months for the Mac Mini. The budget local path wins primarily on privacy, offline access, and unlimited usage; the cloud path wins on speed and zero upfront commitment.
GMKtec EVO-X2

- +Ryzen AI Max+ 395
- +128GB unified LPDDR5X
- +256 GB/s memory bandwidth
- +runs 70B models locally
- -$2
- -000+ price
- -fan noise under AI load
- -Vulkan/ROCm learning curve
The mid-range tier between $2,000 and $2,500 is where the decision gets genuinely difficult. A Strix Halo system runs 70B models locally on 128GB of unified memory. Ollama Cloud Max at $100 per month runs the same models on Blackwell. The raw crossover is around 20 months, but the comparison is more nuanced than that number suggests. Strix Halo delivers about 5 tokens per second on dense 70B models and around 72 tokens per second on MoE architectures. Ollama Cloud on Blackwell will likely outperform on raw generation for dense models. But the Strix Halo has no concurrency limits, no usage caps, and no network dependency. For those curious about scaling local inference beyond a single unit, see our coverage of linked Strix Halo clusters. If you are running multiple model sessions simultaneously, processing batches overnight, or building agent pipelines that run continuously, local hardware earns its keep well before the 20-month crossover because the Cloud Max subscription cannot serve those workloads without hitting limits.
The high-end tier centers on the DGX Spark at $4,699 after NVIDIA’s February price hike. Against Ollama Cloud Max at $100 per month, the raw crossover is 47 months: nearly four years. The DGX Spark wins on CUDA ecosystem depth, fine-tuning performance, and image generation speed. For most inference-only workloads, the cloud subscription is the better deal by a wide margin. The Spark’s remaining advantage is for developers doing training, fine-tuning, and diffusion workflows where CUDA optimization and local GPU compute genuinely outperform hosted inference.
One temporary factor worth noting: DeepSeek V4 Pro currently runs a 75% discount on direct API access that expires May 31, 2026. During this promotional period, the direct API may actually be cheaper than Ollama Cloud for high-volume token generation. After the discount expires, Ollama Cloud’s GPU-time billing model becomes more competitive against per-token APIs, which will shift the math again.
The Framework
Six months ago, the local AI hardware decision was binary: spend the money and own your compute, or pay per token and rent someone else’s. Ollama Cloud adds a genuine middle path. It is the same open-weight models at data center speed, accessible through the same tool you already know, at pricing that undercuts local hardware for everyone except heavy daily users and privacy-bound workflows.
The practical recommendation depends on three questions. First: does your data need to stay on hardware you control? If yes, local wins, and no cloud offering changes that. The privacy argument for local AI hardware is as strong as it has ever been. Second: do you use AI heavily enough that $20 to $100 per month adds up to more than the amortized cost of the hardware over two years? If yes, local wins on economics alone. Third: do you need frontier closed-model capability for complex reasoning and coding? If yes, those API subscriptions remain necessary regardless of what you choose for open-weight workloads.
If you answered no to all three, Ollama Cloud Pro at $20 per month is probably the right place to start. If you answered yes to the first two, the Strix Halo and Mac Mini recommendations in our hardware guides still hold. And if you are not sure, spend a month on Cloud Pro measuring your actual usage before committing to hardware. That month of data is worth more than any buyer’s guide, including this one.
The one certainty is that this three-option landscape is not stable. Ollama Cloud launched weeks ago and has already revised its pricing. Local hardware keeps getting faster and cheaper. Closed-model APIs keep improving at lower price points. Whatever you choose today, plan to reassess in six months. The decisions are real, but the ground beneath them is still moving.




