
Running a single Strix Halo mini PC with 128GB of unified memory gets you comfortably into 70B parameter models, and that alone has been a breakthrough for local AI work. But the models keep growing, and 128GB hits a hard ceiling when you want to run something like Qwen3-235B or GLM 4.6 without aggressive quantization. Sapphire's answer, demonstrated at Embedded World 2026, is elegantly simple: link two boxes together.
The Sapphire Edge AI Max+ 395 pairs two AMD Ryzen AI Max+ 395 mini PCs via USB-C, creating a combined 256GB memory pool for AI inference. Each unit packs 16 Zen 5 CPU cores, 40 RDNA 3.5 compute units in the integrated Radeon 8060S GPU, and 128GB of LPDDR5X-8000 memory. The demo showed the paired system running 235B parameter class models that would be impossible on a single unit, and Sapphire even hinted at daisy-chaining more than two units for even larger workloads. With Computex 2026 targeted for official launch and an estimated price around $2,700 per unit based on comparable hardware like the GMKtec EVO-X2 in its 128GB configuration, two linked Sapphire units would cost roughly $5,400 total, a fraction of what workstation-class AI hardware typically demands.
What makes this more than a trade show curiosity is that the community has already proven the concept works. Enthusiasts have been building their own two-node Strix Halo clusters for months, and AMD itself demonstrated a four-node cluster running a trillion-parameter model. Sapphire is productizing something that hobbyists have validated independently, which is exactly the kind of trajectory that tends to produce practical, reliable products.
How Distributed Inference Actually Works
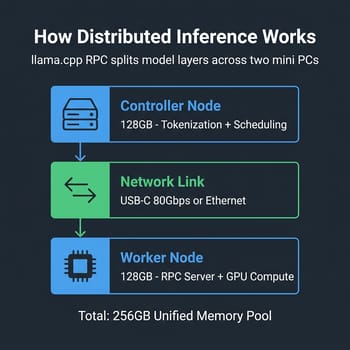
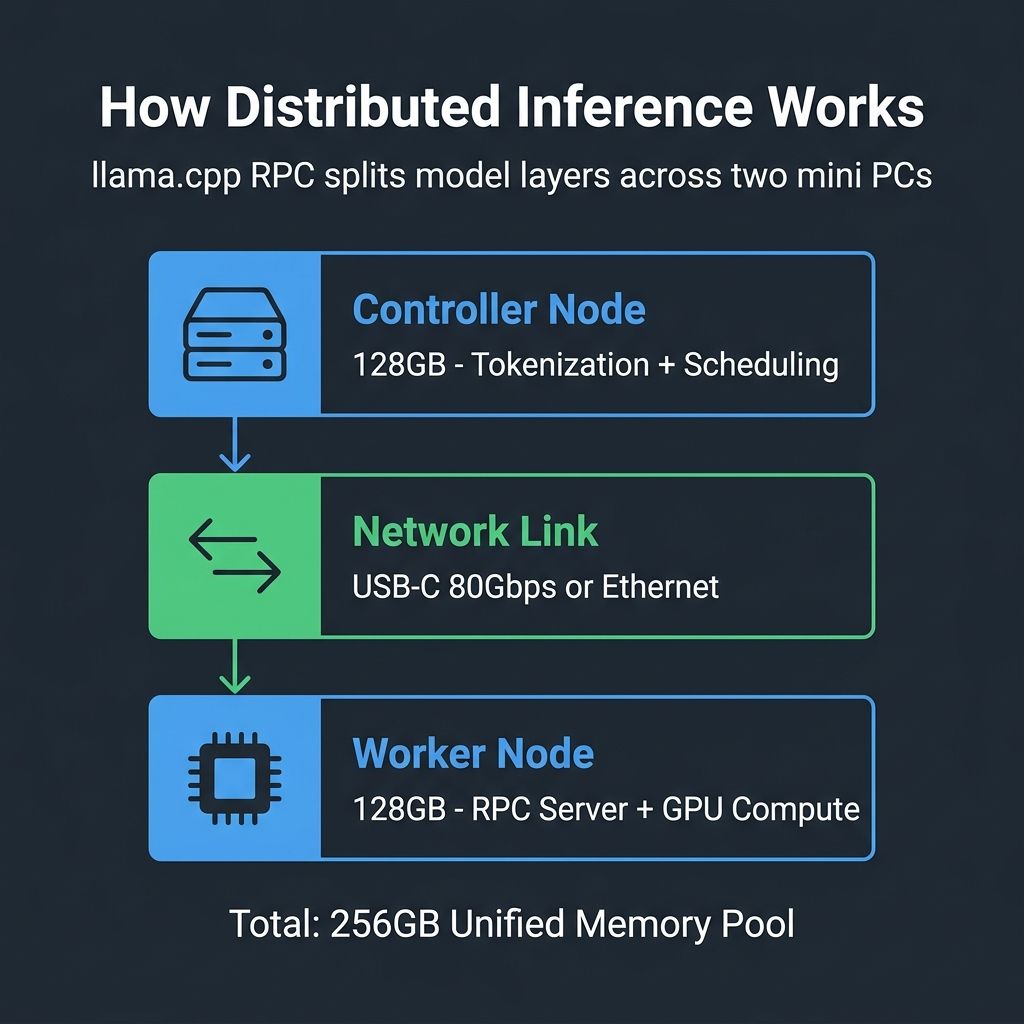
The magic behind linking two mini PCs for AI inference is llama.cpp's RPC (Remote Procedure Call) system, and understanding how it works explains both the potential and the limitations of this approach. One machine acts as the primary controller, handling tokenization, scheduling, and orchestration, while the second runs a lightweight RPC server that exposes its GPU memory and compute resources. When a model is loaded, llama.cpp shards it across both machines at the layer level, placing some layers on the local GPU and the rest on the remote one.
This layer-splitting approach means the model doesn't need to fit in a single machine's memory. A 235B parameter model like Qwen3-235B-A22B at Q3_K_S quantization weighs roughly 101GB, well beyond a single 128GB system's usable GPU allocation of around 96GB. Spread across two nodes with 256GB total, there's ample headroom for the model weights plus the KV cache needed for context. The network link between the machines carries intermediate activations between layers, which is where the performance overhead lives.
The Framework Community's kyuz0 documented this process using a Framework Desktop and HP Z2 Mini G1a over Ethernet, running MiniMax-M2 and GLM 4.6 across the two nodes. The setup process was described as "incredibly easy," which tracks with the broader community experience. Participants noted that latency rather than bandwidth was the primary bottleneck, and that improvements to tensor parallelism in llama.cpp would help multi-node setups further. If you can configure a network connection and run a Docker container, you can build a two-node cluster.
Sapphire's prototype currently uses USB-C for the inter-node link. Some Strix Halo systems ship with USB4 ports rated at 40-80 Gbps depending on the model, which provides substantially more bandwidth than Gigabit Ethernet. Fudzilla reports that Sapphire plans to switch to Ethernet for the production version, likely with dual LAN ports to support dedicated inter-node networking. This makes sense: Ethernet is more standardized for this kind of distributed computing, and dedicated networking avoids contending with other USB traffic on the same controller.
The Performance Reality


Benchmark data from community builds gives a realistic picture of what dual-node Strix Halo clusters deliver. Qwen3-235B-A22B is a Mixture of Experts model with 235B total parameters but only 22B active per token, which makes it particularly well-suited to distributed inference. Because only a fraction of parameters activate per token, generation speeds on a dual-node cluster with ROCm can reach roughly 10-15 tokens per second, fast enough that responses feel conversational rather than painfully slow.
The MoE architecture deserves emphasis here because it fundamentally changes the performance equation. A dense 235B model would be far slower, since every parameter must be read from memory for each token. MoE models like Qwen3-235B activate only a fraction of their parameters per token, so inference speed scales with the active parameter count rather than the total. This is exactly the kind of model architecture where having more total memory matters enormously while the bandwidth bottleneck remains manageable. You need 256GB to store the full model, but the per-token compute load resembles a much smaller model.
Dense models tell a different story. Running a fully dense model in the 200B+ parameter range across two nodes would mean much lower generation speeds, likely 3-5 tokens per second depending on quantization. That's still usable for batch processing or slow-but-steady chat, but it's approaching the threshold where the experience starts to feel sluggish. For context, our single-node Strix Halo guide documented 5 tokens per second on a 70B dense model as the community's minimum for tolerable conversation.
The network link between nodes introduces latency that doesn't exist in a single machine. Each layer transition that crosses the network boundary adds a small delay, and these accumulate across the model's depth. The overhead varies significantly depending on the network link speed, model architecture, and how layers are distributed, but it's meaningful enough that Sapphire's eventual switch to faster Ethernet and potentially dedicated inter-node protocols matters for squeezing out maximum performance.
Cost Comparison: What $5,400 Gets You
The value proposition of two linked Strix Halo mini PCs becomes clearer when you compare alternatives for running 235B class models locally. A dual Sapphire cluster at an estimated $5,400 total sits in interesting territory against established competitors, each of which makes different tradeoffs between memory capacity, raw speed, software maturity, and price.
NVIDIA's DGX Spark costs roughly $4,000 for a single unit with 128GB of unified memory, enough for 70B models but not 235B class workloads without aggressive quantization. NVIDIA does support linking two DGX Spark units via ConnectX networking, but at $8,000 total, that's nearly 50% more expensive than the Sapphire pair. The DGX Spark's advantage is the CUDA software ecosystem, which remains more polished than AMD's ROCm stack, and significantly faster prompt processing thanks to the Blackwell architecture's Tensor Cores.
Apple's Mac Studio with M3 Ultra offers up to 192GB of unified memory at around $5,000-6,000, with 819 GB/s of memory bandwidth that roughly doubles what each Strix Halo node provides. For models that fit within 192GB, the Mac Studio will deliver faster single-node inference. But it tops out at 192GB without any official multi-unit clustering option, and the macOS ecosystem for distributed inference across multiple machines is far less developed than the Linux-based llama.cpp RPC stack.
The DIY multi-GPU route remains the performance king. Three used RTX 3090s with 72GB of total VRAM and 936 GB/s of memory bandwidth per card will generate tokens significantly faster than either the DGX Spark or a Strix Halo cluster for models that fit in 72GB. But those models top out at approximately 70B parameters, and the setup draws over 1,000 watts compared to roughly 280W for two Strix Halo mini PCs. For the 235B class specifically, the Strix Halo cluster is the most affordable path to sufficient memory.
AMD's Trillion-Parameter Vision
Sapphire's two-unit demo is actually the modest version of where AMD sees this technology heading. AMD's own developer team demonstrated a four-node cluster of Framework Desktop systems running distributed inference of the trillion-parameter Kimi K2.5 model using llama.cpp RPC. Four nodes means 512GB of combined memory, enough to load truly massive models that would otherwise require enterprise hardware costing tens of thousands of dollars.
The AMD walkthrough describes a design that maps extremely well to Ryzen AI Max+ systems: each node contributes a large pool of GPU-addressable memory and compute, and llama.cpp shards the model across all nodes at load time. One machine serves as the primary controller while the others run lightweight RPC workers. From the model's perspective, layers are distributed across all available devices regardless of whether they're local or remote.
This trajectory matters because it suggests Sapphire's clustering approach isn't a gimmick but rather the consumer-facing implementation of a pattern AMD is actively developing and supporting. If the software stack continues to mature and vendors like Sapphire make the hardware plug-and-play, "mini PC clusters" could become a standard approach to scaling local AI, much like how network-attached storage evolved from a hobbyist project to a mainstream product category. The community building self-hosting setups with these machines is already thinking about this kind of stacking.
Who Should Care About Clustered Mini PCs
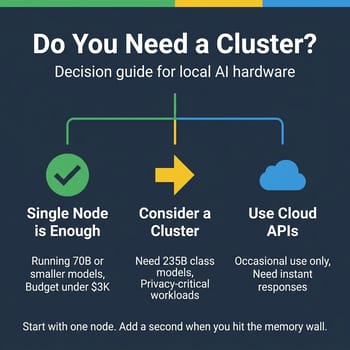
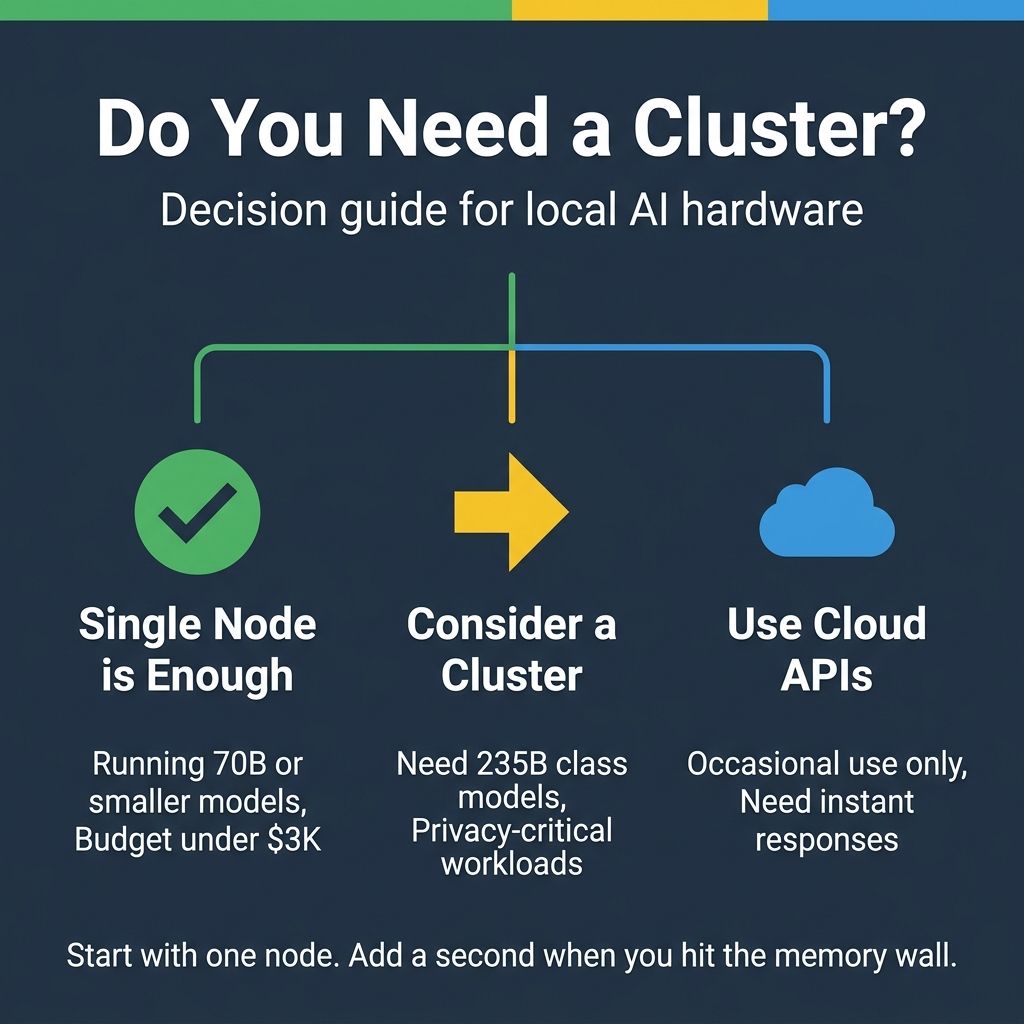
Before getting excited about a dual-unit cluster, it's worth asking whether you actually need 235B parameter models. Many practical local AI use cases, coding assistance, document analysis, chatbot development, work perfectly well with 70B or even 30B parameter models on a single Strix Halo system. A quantized 70B model on one box often outperforms a poorly quantized 235B model stretched across two, because quantization quality directly affects output coherence. The right question isn't "can I run the biggest model possible" but "what's the smallest model that meets my quality requirements."
That said, there are genuine use cases where bigger models make a meaningful difference. Researchers benchmarking model behavior across sizes need access to frontier-class models. Developers building RAG systems with long context windows benefit from the additional memory, since 256GB lets you keep a large model loaded alongside substantial context and vector databases simultaneously. Privacy-sensitive applications in healthcare, legal, or finance may need to run the most capable available models entirely on-premises. And some languages and specialized domains simply perform better with larger models, where no amount of quantization on a smaller model can compensate.
The setup complexity is real but manageable for anyone comfortable with Linux. You'll need Fedora 42 or a recent Ubuntu distribution, working ROCm drivers, and familiarity with running containers. The llama.cpp RPC setup itself is straightforward, essentially starting a server process on one machine and pointing the other machine at it. Community guides walk through the process step by step, and the toolbox containers available for Strix Halo dramatically simplify the initial configuration. If you've followed our guide on BitNet and 1-bit LLMs on budget hardware, you have more than enough technical background to set up a cluster.
Windows users should understand that this is currently a Linux-first workflow. While llama.cpp runs on Windows, the ROCm stack and RPC server configurations are primarily tested and documented for Linux. AMD's official cluster demos all use Linux environments, and the community toolboxes that simplify setup are Linux-native. This may change as the ecosystem matures, but for now, plan on running Linux on at least the worker node.
What to Watch For
Sapphire's Computex 2026 launch will reveal critical details that are still unknown: final pricing, the production interconnect solution (USB-C, Ethernet, or both), and whether the software experience will be truly plug-and-play or require manual llama.cpp configuration. The transition from USB-C to Ethernet for the production version suggests Sapphire recognized that USB-C, while adequate for demos, has practical limitations for sustained inter-node communication.
The broader implication is more interesting than any single product. If Sapphire succeeds, other vendors will follow. Multiple mini PC manufacturers already ship Strix Halo systems, and the llama.cpp RPC infrastructure is open source and vendor-agnostic. There's nothing stopping MINISFORUM, GMKtec, or Beelink from offering their own clustering solutions or simply marketing their existing USB4-equipped systems as cluster-ready. The building blocks exist today for anyone willing to set them up manually.
For readers who want to start experimenting now rather than waiting for Sapphire's launch, any two Strix Halo mini PCs connected over Ethernet can replicate this setup using llama.cpp RPC. The hardware is available today, the software is free and open source, and the community has already mapped out the configuration process. Sapphire's contribution will be making it easier, but the capability is already here for those willing to build it themselves.
MINISFORUM MS-S1 MAX

- +Dual 10GbE for cluster networking
- +USB4 V2 80Gbps
- +PCIe x16 expansion
- +Built-in 320W PSU
- -Premium pricing
- -RAM soldered
- -Larger footprint
GMKtec EVO-X2

- +Multiple RAM configurations (64/96/128GB)
- +Competitive pricing
- +Quad 8K display output
- -Dual 2GbE only (not 10GbE)
- -RAM soldered
- -Inconsistent availability



